
Attention Modules – Results
Wow! The HPC (High Performance Computer) on UNT’s campus has been in high demand, so one of my models was waiting in a queue for 6 days, 10 hours, and 37 minutes! I still have models that are pending, but a week after starting this crazy ride with Attention Modules, enough of the models we have made have finished training, so we can finally discuss some results!
For a more complete discussion of what all these different networks are, see last week’s post concerning Attention Modules in Deep Neural Networks.
First off, the networks that we will discuss today include the plain ResNet50 (from weeks ago), A ResNet50 with Bottleneck Attention Modules from Park et. al., Xu Ma’s SResNet50, as well as two modifications I made to Xu’s network that I (fittingly) call SResNet50 With Skips and SResNet50 With Dilation.
Without further ado, let’s see how the testing accuracy looks over the course of training!
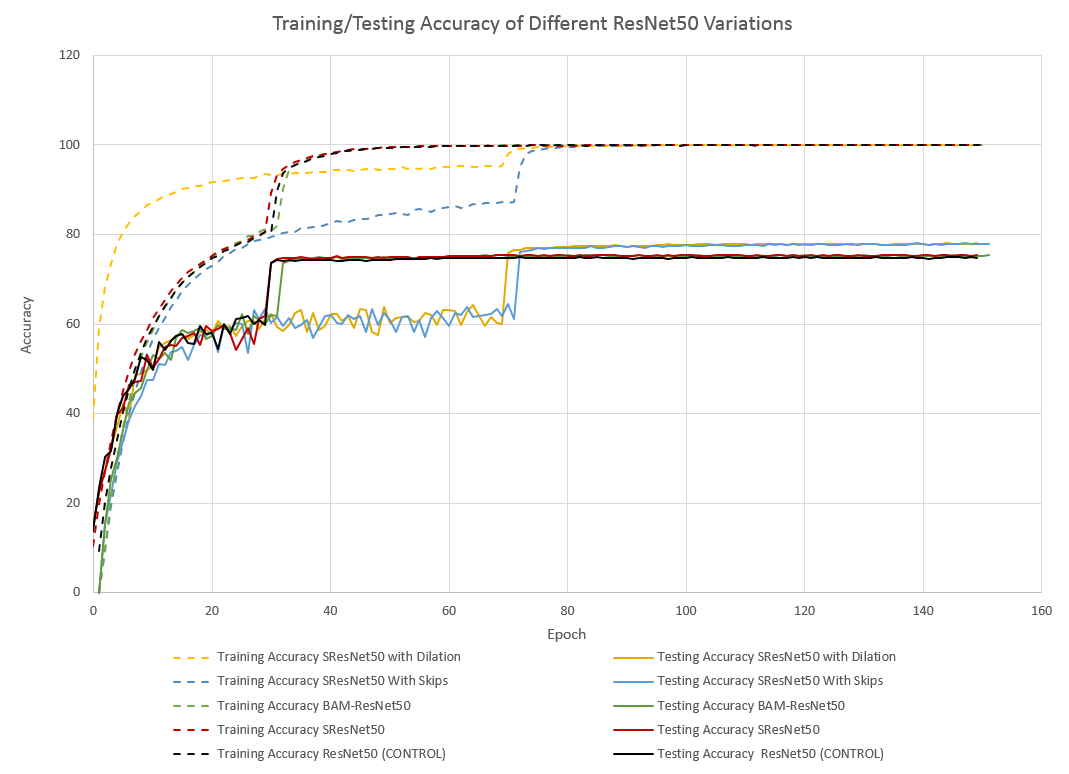
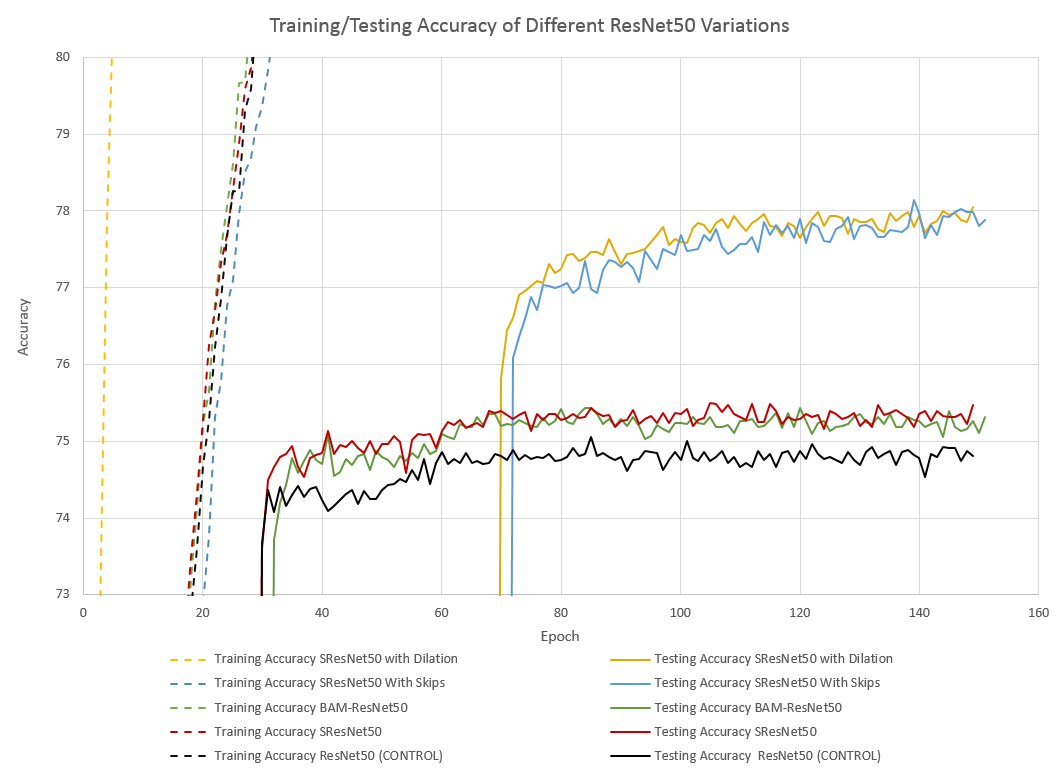
As clear from the graphs (especially Figure 2), SResNet50 and ResNet50 with BAM perform marginally better than the plain ResNet50 (in black) in our training set up. The two other networks (SResNet50 With Skips and SResNet50 With Dilation), however, both show a distinct improvement. The network with skip connections in its attention module even approaches 78.1% accuracy during some epochs.
While these results are not state of the art–they’re peanuts compared to EfficientNet’s supposed 91.7% accuracy on CIFAR100–they are a noticeable improvement over a regular ResNet50, which leads one to believe that using these forms of attention module on a more accurate base model might provide substantial benefit.