
Attention Modules – An Introduction
One of the hot topics currently in Image Classification is the idea of Attention, inspired by our own visual biological attention. It makes intuitive sense that if you weight the important parts of an image, then the model will more accurately predict what that image portrays. Thus, from what I have read, it seems that computer scientists have tried to implement attention mechanisms in computer vision for a long time, but only in recent years, after the re-emergence of neural networks have the attempts been useful. This will not be a survey of the history of attention mechanisms, but instead a brief highlight of some of those that we have played with in UNT’s 2019 Autonomous Vehicle REU.
Perhaps one of the most prominent attention mechanisms we have used is the Squeeze-and-Excitation Block, by Jie Hu, et. al., which focuses not on the which regions of the image are most useful for classification, but instead on which channels are most useful. At first, this may seem counter-intuitive, since we are accustomed to thinking of image channels as representing colors or transparency, but upon further inspection, this makes considerable sense, since in later parts of a deep neural network, the channels in a layer do not represent color, but rather the presence of different features found in the image by a convolution operation.
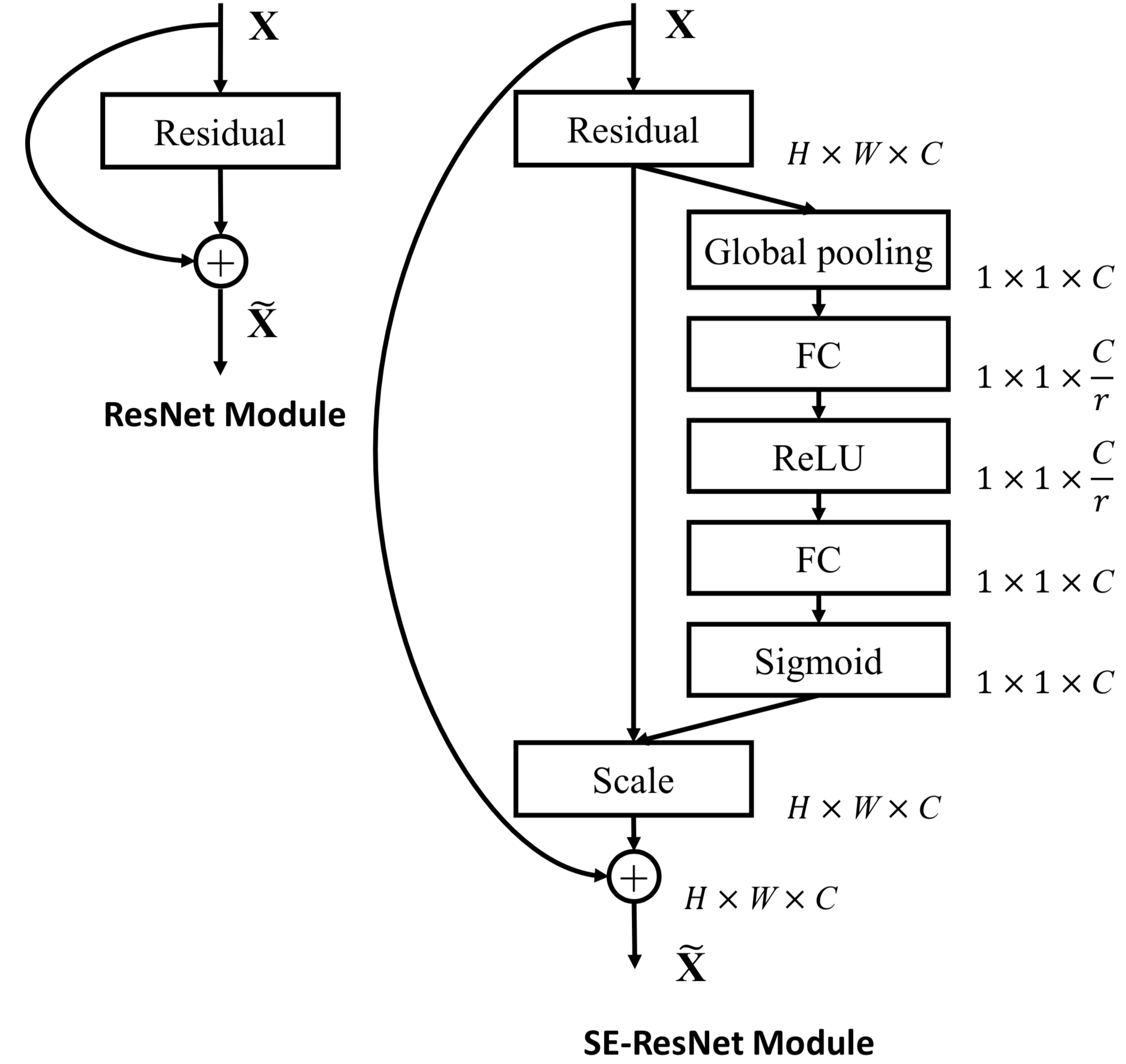
This clever module can be inserted with little computational overhead into any base network with convolutional operations. Put simply, it finds the average value of each channel of its input, then feeds those through two fully-connected layers to (hopefully) re-balance each channel’s “importance”. It then multiplies the original input by these weights to filter out the unimportant features. Figure 1 shows a diagram of this, from the original author’s GitHub repository. These are simple but powerful and can (with all other factors constant), improve the validation accuracy of a ResNet50 by a little more than a percentage point1. I strongly encourage everyone to read the original paper several times. Most of the other attention modules discussed in this post are based on the SE Block in some way or another. In another post, I will describe the results that I found after testing the placement of the SE blocks in different parts of a ResNet.
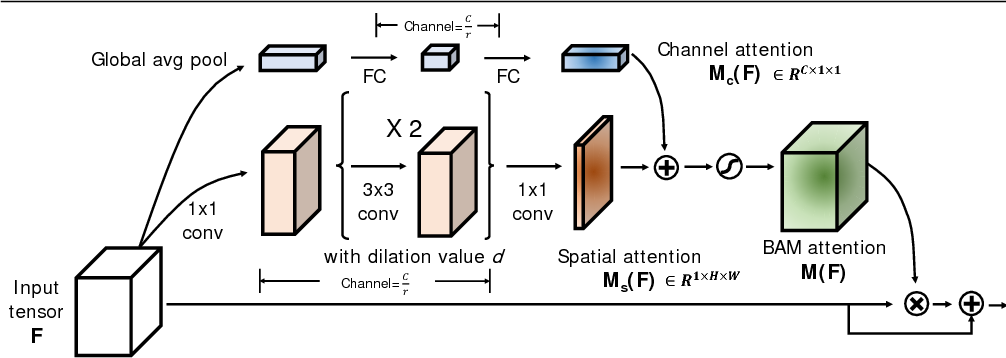
The second type of Attention Module that our research team experimented with is the Bottleneck Attention Module (BAM). BAM attempts to focus on spatial regions in the image, instead of particular channels. It uses several additional 1x1 convolutional layers to attempt to focus on the spaces in the image that contribute most to the classification, as shown in Figure 2. BAM has a modest increase in classification accuracy2.
Inspired by BAM and its cousin CBAM, Xu Ma the graduate student on our research team created an even smaller spatial attention module and added it to a ResNet50 to make what he calls the SResNet50.